The Self-Driving IDE is Coming
I’ve got something new for you today. At least, it’s new to me, and hopefully it’s new to most of you as well. It is a powerful idea that is emerging in the Coding Assistant space, as we build out the Cody experience and learn our way around this new world.
I’ll be talking today about a dimension of the Coding Assistant space that nearly everyone has been punting on: Specifically, crafting a universal cross-IDE experience. And I’m going to connect it at the end to autonomous AI agents, which are the New Hotness.
I’ll do something a bit unusual today and tell it all top-down. There’s a lot to cover and I want to make sure we’re all on the same footing when it comes to terminology and whatnot. So no stories, jokes, buried ledes, etc.
The main downside to top-down is that it’s hard to convey how excited I am about all this. Hopefully you’ll have caught that bug by the time we finish. But yeah. Exciting times are ahead for programmers.
There are multiple angles to consider, and multiple entry points into this graph, so let’s just start with the price tag, shall we?
Features vs IDEs
In the coding assistant space, you are immediately faced with the inconvenient reality that there are a good 15+ popular IDEs with powerful enough extension systems to create a rich plugin like Cody. This list includes the usual suspects: VS Code, Visual Studio, the JetBrains family, Eclipse, NetBeans, Xcode, Android Studio, Emacs, Neovim, etc. No surprises.
Well ok, NetBeans is a perpetual surprise. But otherwise, pretty straightforward.
Few, if any, of these popular IDEs and editors thought to look closely at their predecessors. Instead, they all started from the ground up with their own notions of what an IDE plugin API ought to be. And they wound up with 15+ very different visions, though ultimately implementing broadly the same-ish set of features.
To make this a bit more concrete, this is the problem you have as an IDE plugin developer. Note that I am showing you what it looks like for a Coding Assistant, but we ran into a very similar matrix at Google in the code-intelligence space, with feature-rows and the columns were programming languages. They both have the same basic challenge: Coverage.
| Features x IDEs | VS Code | JetBrains | Neovim | Xcode | Emacs | Android Studio | … |
|---|---|---|---|---|---|---|---|
| Chat | |||||||
| Completions | |||||||
| Commands | |||||||
| Inline Edits | |||||||
| Chat history | |||||||
| Enterprise controls | |||||||
| Custom prompts | |||||||
| … |
This grid extends to, say, 15 columns, and then the vertical feature list is effectively open-ended, limited only by your ability to fill in those squares with green checkmarks.
One thing we learned way back at Google in 2009-2010 was that if that grid is too sparse, people won’t trust your product because it feels “unreliable”. So you can’t push too far to the right, adding more IDE clients, unless you can spend enough to implement the whole feature set for each one.
But this feature matrix is massive. You have to re-implement every single feature 12 to 15 times, or else hope you can drum up enough community involvement to get other people to do the work. And Cody’s feature set is still growing surprisingly fast, so the matrix gets harder by the week.
Even if you do get community help with your clients, you’ll still need to own the implementations of at least the core half dozen IDEs in-house, to ensure a high enough level of support for both the community and for your enterprise users.
Writing IDE plugins is incredibly un-glamorous work that takes a lot of engineers, often with highly specialized skills. These IDE APIs are often ancient, crufty, and at times very finicky/particular. It’s considered almost a fringe of the industry. “Nobody gets promoted for writing IDE plugins”, as they say. It’s hard even to find people who are good at it.
This is why the browser plugins and IDE plugins from most companies are clear afterthoughts. Because it costs a lot, and not many people really want to work on that stuff.
That pretty well sets the context for our first problem, which is that Coding Assistants have turned this whole age-old equation on its head. Coding assistants are very, very important plugins: Plugins that every single developer on earth should be using today, unless they’re still riding a horse to work. And it’s clear that these plugins are going to be doing more and more. You can’t really make them an afterthought.
So let’s revisit the math again, and see if we can make this work.
Too rich for their blood
Let’s say you want to support N = 12-15 IDEs. You will likely need at least N/2 engineers, but it can be N or even a multiple of N, depending on how complicated your plugin is.
What upper bound on cost are we looking at here? Well, it turns out, somewhat counterintuitively, that plugins can grow so monstrously large that they rival or surpass the size and resource consumption of their host system. I could list dozens of examples, but a good one is Android Studio. It’s “just” an IntelliJ plugin, or really a set of collaborating plugins, orchestrated into a powerful and differentiated IDE in its own right – but a plugin, nonetheless.
Another cool example is the WeChat Uber clone plugin that operates in Vancouver, B.C. It’s a huge app that’s just a plugin for another app (WeChat). Once you create a platform for hosting extensions/plugins, there is no real ceiling on how big they can get, other than OS resources. Even a browser can be considered a cross-platform “plugin” for operating systems, in turn with its own plugins, and so on. Some of these plugins – Chrome, WeChat, Android Studio – become dominant platforms in their own right.
What does a big plugin cost to build? Android Studio has a fairly large (20+) team of dedicated developers, PMs and designers working, if not even more these days. That’s a hefty price tag to pay for building something that you’re giving away for free. I can assure you that Google would not be investing in Android Studio if they didn’t see it as a competitive advantage to offering a great development experience for Android.
But wait, you say – most plugins never get even _close _to that big, do they? Most companies that offer any plugins at all, e.g. an Amazon Chrome extension or whatever, put at best maybe an engineer on it, and then they’re only part-time after it has launched and is stable. Most companies that have plugins, ironically, do not have plugin developers. They do the minimum and put it on hold, just like your build system. Like I said, nobody wants to work on it, because nobody gets promoted for that kind of work in our industry. Sucks but it’s the reality on the street.
Well. Vendors of coding assistants face this exact problem of needing plugin developers. A lot more. They want to add features, and they want to work in all IDEs, but the price tag is way too steep for them. Few startups can justify 20 devs working on a plugin that works across all IDEs, before they’ve proven they can make it work in one! And few large companies have senior leaders who understand the value proposition of weird programmer tools well enough to spend 20 developers on such a boondoggle. “It’s better to just make improvements on the backend,” they’ll say, and they’ll cut the plugin team from 20 down to like, maybe Joe and Tim, but Tim can only work on it at night.
To be clear: Sourcegraph is a coding assistant vendor, too, with characteristics of both a startup and a larger company. But we are actually rolling up our sleeves and doing this work, as we’ll see below.
So what do most coding assistant vendors do instead? They all pick a slice of that matrix to go deep on. Some of them choose horizontal rows: They offer their plugin in all IDEs, but it doesn’t have very many features. You get completions, maybe some chat, that’s it. Others choose vertical columns: They go super, super deep in one or two IDEs, and ignore all the others, crossing their fingers and hoping that all developers will just switch to VS Code someday soon.
Good luck with that. Emacs is pretty close to fifty years old, which I suspect means it’s gonna outlive us all.
Designing a universal solution
At Sourcegraph, we’ve decided to tackle the whole matrix. Though if you barged in today and did an audit, you would find that we are still pretty solidly in the vertical-column crowd today, going deep with a couple of IDEs. Very deep; we have all the features listed in the matrix above and more. We intend to bring that depth to every IDE. But it’s currently only in VS Code and, in a couple weeks, JetBrains.
But wait… tackling the whole matrix is crazy, right? I just finished saying nobody can afford it. So let’s dig in a little.
First, in order to turn the Features x IDEs matrix from an intractable NxM problem into a quasi-tractable (though still expensive) N+M, we use the bog-standard helper-binary architecture, with a separate process running most of the business logic, and the clients being as thin as practical. In Cody’s case, we have most of our logic baked into what I’ll call our Cody Client Backend, which is largely in TypeScript and Rust, and is designed to be shared across IDEs.
For the rest of this post I’ll use CCB when I mean Cody Client Backend, or just “backend” when it’s unambiguous.
This CCB design is not especially innovative in itself, and others are doing this kind of thing as well. It’s an idea older than LSP, the now-ubiquitous Microsoft Language Server Protocol, and certainly popularized by LSP in recent years. The design is an admission that your IDE sometimes can’t do everything itself, and needs to farm out smarts to a helper binary or remote service. This admission took the industry, especially in the JVM world, a surprisingly long time to admit to themselves. But it is now commonplace, with JSON-RPC being the protocol lingua franca.
Even with the hub-and-spoke model, the engineering is still a high hurdle. Even though the helper binary does most of the heavy lifting, from mirroring your IDE state to curating context to mediating with the LLM, there is still a huge amount to do on the clients. Every major feature – chat, completions, edits, test gen, doc gen, etc. – is like a miniature application which itself includes:
- Its own surprisingly – shockingly, even – complex user interface, with error feedback, authentication and other concerns.
- A JSON-RPC protocol, usually with multiple round-trips, including the type modeling on both the client and the backend.
- A shared IDE-agnostic-ish implementation in the CCB.
- Registration, deregistration, disposal/cleanup, lifecycle management, and a zillion listeners. Every IDE plugin has exactly one zillion listeners. It’s just how you do stuff.
- Accessibility controls, enterprise controls, automated UI tests, and other stuff that can’t necessarily be handled properly in the shared backend because of IDE-specific requirements or conventions.
That huge list of work is required for every single new feature you add to Cody, or really any coding assistant using this model.
For Inline Edits alone, a feature I’ve been adding to JetBrains for our imminent GA, we had to extend the JSON-RPC protocol with several dozen new types, half a dozen requests and notifications, multiple round-trips requiring a sequence diagram to fully explain, several edge cases and quirks that clients need to know about and handle, and an ever-growing set of mini-features that need implementations in TypeScript and Kotlin. And from now until forever, we need to do it all again for each new client we bring on.
Add up the protocol for all the features we support today, and we have 60+ JSON-RPC requests and notifications in our Cody IDE Client API, and as many message and parameter types. I’d also estimate it’s growing by about a call a week. Sure, it isn’t that big for a production API. But to an outsider it seems a bit excessive for something that does chat and completions.
When I first looked at this protocol closely back in January, I thought it was completely insane. But now, with several months of deep hands-on experience, I’ve come to understand that it’s actually completely insane. It’s stupidly ambitious, and in fact arguably somewhat contentious in engineering – or at any rate, despite its advantages, many of our engineers are also concerned about the downsides.
The main downside, of course, is that it’s easily 6 to 9 months of work today to create a new Cody client, even though it’s technically “just” wiring up UI. But really, it’s all that work I mentioned above, multiplied by Cody’s large and evolving feature set.
Basically the reason I’m writing this blog post is to explain why even though we are taking the hard road with no shortcuts, I think it will give us yet another advantage in the race. One that I think we may have stumbled on a bit inadvertently.
LSP for the AI age
You want it to be easy to integrate clients with your coding assistant. That implies a simple protocol. Why, then, is Cody’s protocol so huge? Why can’t we just have, you know, showUserCompletionAt(cursor), sendChatAndGetReply(prompt), and ship that to millions of eager developers around the world?
The historical driver for our protocol design was that we wanted the VS Code Cody team to be able to innovate unfettered by platform concerns. Un. Fettered. Like, just don’t think about it, ever. And we also wanted the team to build an incredibly rich and helpful user experience that works with you literally as you are typing, no matter what you’re doing in the IDE.
To make a very long story short, what we came up with is probably closest in spirit to LSP. Our Cody client backend acts a bit like an advanced LSP server, but instead of serving up code intelligence metadata, it mediates interactions with the AI.
The fastest approach for the VS Code Cody team was to code directly against VS Code’s API, without worrying about some intermediate facade that we’d be building in parallel for other clients. So the Cody platform engineers, led by the inimitable Olaf Geirrson, didn’t bother with an intermediate parallel API. They just made VS Code’s API the platform.
A good extension API should be general. It should be able to hook into just about anything the IDE can do, augment or change it, and bring entirely new functionality altogether, possibly in novel ways suitable to the new domain. Nearly all IDEs have an extension API that can do all these things, and as such could have been our design archetype. But nearly all of them made decisions, both in their APIs and in their extension languages, that haven’t aged all that well.
VS Code, in contrast, is new-ish at only about a decade old, and its API is actually fairly clean and modern. It does a good job of expressing the actions and workflows that an IDE can perform programmatically, the structure of extensions, and how they interact with VS Code. Or at least, it does a much better job than the other IDEs we looked at.
Hence, Cody’s client protocol, with all its requests and notifications, is adhering as closely as practical to VS Code’s IDE extension API, infused with the meaty aroma of LSP. We implement a sizable subset of the overall API, the part our VS Code extension needs for Cody, and stub out the rest.
The VS Code team didn’t intend for their API to be used this way, so it’s full of VSCode-isms, and we’ve had to make various changes. And it’s not incredibly full-featured, so we’ve been adding to it here and there. But it does have enough to cover the core functionality for most editors, which made it a great starting point. Kudos to the VS Code team for having done pretty much everything right from the very day they started on this project all those years ago. Except for locking down their private APIs in a monopolistic fashion. But you know. Good game, mostly.
The VS Code halloween costume
So as we’ve seen, Cody is heavily inspired by two very successful APIs in adjacent domains, and surprisingly to us old-timers, both are from Microsoft. How the foot of the world changes to the other hand, as they say. And although I’m sure these choices we made all sound very reasonable now, given our constraints, I’m certain that the facade of reasonableness will tear away like wet toilet paper once you see our actual architecture.
Here’s what we do. Ready yourself.
For JetBrains and other clients, we run our VS Code extension–the one our VS Code Cody team built–outside of VS Code, in Node.js. There is no VS Code anywhere to be seen. We are literally only “running” the extension. It’s like The Truman Show: We’ve put it in a bubble that looks just like the outside world, but behind the scenes is a bunch of production infrastructure that fakes it all.
The bubble is our Cody client backend, a TypeScript/Rust backend, which makes your IDE look, to the extension, like it’s VS Code. It’s a costume. The extension happily sends and receives VS Code messages, like “make this document edit”, or “show this error notification”, and the CCB and your IDE conspire to have your IDE handle it all.
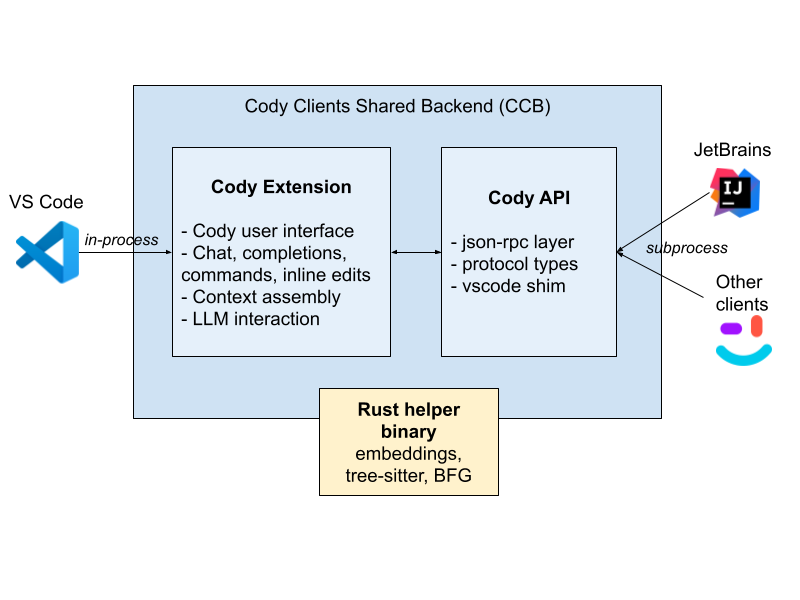
Figure 1: Cody multi-client architecture
To draw an analogy, this is like saying we really liked Bob’s home security system, since it does a really good job of recognizing and handling Bob’s friends and family. So we cloned Bob’s system, and now you can have that system too. All you have to do is have your family dress up like Bob’s family to fool the security system into thinking you are them.
Yeah.
So that, of course, is somewhat unconventional, and I can tell you it’s technically no picnic. The protocol is multi-hop, bidirectional, asynchronous, highly stateful, real-time, chatty, and is essentially a powerful black-body emitter for new radioactive bugs that take days to track down.
Oh, also, “stateful” is computer-science terminology for “really really expensive”. We have made a very expensive choice. It’s the necessary choice, because Cody needs to follow exactly what you are doing in real time, potentially from the Cloud. That means it needs a mirror of your work, kept up to date in real time.
Why does Cody need all that state? For the same reason that LSP needs state: It’s a separate process, running outside your IDE, that is helping you in real time, as you type, with knowledge of all of the surrounding context. Because it doesn’t share memory with the IDE, it needs to track your editing session in real time, just like LSP does. It receives a stream of every source document that is opened, changed, or has its selection range or caret position(s) changed, and works off that mirror. It communicates any changes the AI makes on the mirror back to the client. And yet, amazingly, it’s a lightning fast and completely seamless user experience.
This should all be pretty familiar if you’ve used an LSP language server. We would have liked to use LSP, but it wasn’t designed to be general-purpose enough to meet Cody’s needs, not by a country mile. Though, I suppose if it had been, then it would be as big as VS Code’s API, because coding assistants don’t just deliver code intelligence; they need to be able to operate your entire IDE.
Cody the puppeteer
The 100+ RPCs in Cody’s protocol, once wired up in a client, are effectively nerves, or puppet strings, whichever metaphor you prefer. Using Cody’s protocol, the LLM can of course directly edit your code, and in a rather sophisticated way, with streaming, undo, retry, diffs, and other goodies all handled mostly on the CCB side, so they will all be reusable for our next dozen Cody clients.
But going beyond editing your code, it can do things like issue commands to your IDE. Most IDEs have a generic Command infrastructure that allows you to trigger various actions programmatically through a messaging bus. And LLMs speak IDE. So if the LLM has a channel over the JSON-RPC Cody protocol into your client, then it can effectively operate the IDE for you, on your behalf. Or on your bewhole. Who knows. We’re in new territory here. Is it dangerous? Uh, sure. But that’s why we have source control and firewalls and admin controls and such. The important thing is that it’s a practically unbounded accelerator over the next few years. That’s worth a little living dangerously for.
You can draw a parallel to those big ugly units they used to put on cars to enable them to be autonomous. The early self-driving cars were just regular cars that had a robotic driving unit attached that could operate the wheel, pedals, etc. They had a gazillion cameras and sensors and wires and connections, because they needed to be able to do anything a driver or passenger could do with the vehicle. And of course it was all in constant communication with local and remote models.
Cody is much like one of those self-driving units, except you drop it into your IDE, not your car. And, much like AVs, IDEs are quite complicated beasts. So Cody, too, has a gazillion cameras, sensors, wires and connections, so that the LLM may ultimately perform operations with the IDE much faster than you can perform them yourself.
That, folks, is how we wound up with this crazy protocol. It’s going to be a pretty big hunk of work to implement it in the top, say, dozen IDEs. But we’re exactly the shop to do it, since it’s closer to our wheelhouse than it is for most dev shops. And for us, it’s a differentiator, whereas for most startups it’s a risky gamble and for most big companies it’s a distraction. So we have more skin in this game, and we are willing and able to pay the price tag to make our vision happen.
Now you are armed with everything you need in order to see where this fits in with autonomous AI agents.
The Emperor’s New Agent
Agents are all the rage. It’s what everyone’s working on. It’s the fashionable stuff. I’ve been talking about the grungy, unfashionable stuff, the poor saps working down in the steam pipes below the manholes in the industrial part of town – not just frontend work (ugh), not just desktop frontend work (yargh!), but desktop plugin frontend work (waaaaaaugh!) Nobody in their right mind talks about that stuff, let alone works on it.
So all the focus is on models. Which is lovely. It’s ducky. It’s great. They’re doing great. Everyone’s making these really fancy brains that can handle multi-step workflows. You’ve seen the demos. You’ve heard the hype.
What nobody seems to be pointing out about the Emperor’s ol’ wardrobe is that these fancy new Autonomous Agent brains are still in JARS, wired up to toy interfaces they purchased from a recently renovated Toys backwards-’R’-Us. All their UIs are web UIs. They’re toys.
In fact the problem is so pervasive that it has become commonplace for companies making Agents to target nontechnical audiences, such as, say, CEOs who haven’t coded in 45 years, or aspiring founders who want to make a cooking app. All you see coming from agents are web and simple mobile apps, with no real ability to program them after they are generated.
Meantime, none of these teams even want to think about wiring up their agent to an IDE.
I’ll give you 3 guesses why, and the first two don’t even count. I’m so generous.
The Meta-IDE
Cody is of course doing all sorts of other interesting things that I’ve talked about in the past, things that only Cody will be able to do because of our code intelligence, search, and other scalable content/RAG strategies that Sourcegraph has specialized in for the past decade.
But this idea, the idea of Cody-plugin-as-IDE-orchestrator, expands our horizons to encompass multi-step agent-driven workflows that can drive not just one IDE, but soon all IDEs.
We already have several distinct modalities, including various flavors of autocompletion, chat, commands, and inline editing. Each of these is a distinct way of interacting with an LLM to get some work done. But since the entire IDE is automatable, there’s no reason you can’t also have the LLM help you with the tedium of doing things like upgrading plugins, re-syncing database settings, creating run configurations, or pretty much anything else you might want to speed up as an IDE user.
We’re headed towards a world in which Cody can be your first stop for any action you want to take in your editor/IDE of choice. It will be able to operate the editor for you, write code on the fly for new plugins and functionality that you’d like it to deliver, and essentially be a concierge or driver to which you are increasingly issuing higher-level directions. Cody already feels a lot like this to me today, especially with the inline-edits (“fixups”) feature. I like to let Cody do most of the driving, whenever possible.
Figure 2: Inline Editing with Cody in JetBrains
At some point Cody will be able to do it all, and do it in parallel. I look forward to talking to it while I’m typing, and getting multiple things done at once. At that point the underlying IDE starts to become disintermediated, because in time, Cody will make the LLM genuinely better at using the IDE than you are yourself. It doesn’t matter how many Emacs keystrokes you’ve memorized in the last 35 years (sigh), because Cody knows literally all of them. Right? It’s hard for me to let go, but then again, I’m lazy, so I’m sure I’ll get used to delegating.
And there’s no reason Cody has to be the only orchestrator; it can be a meta-orchestrator for other agents. If Sourcegraph really does wind up being the only team to tackle this problem of fully automating IDEs in a universal way, then Cody may well become a popular destination for wiring up agents that currently only have web UIs. In other words, the Cody Platform – something I have been thinking about a lot lately. But that’s a post for another day.
I wouldn’t bet on anyone else doing this, at least not in a universal way. As I’ve argued, it’s expensive and a bit of a one-way door type of decision, because it requires a complex middleware architecture and much more work on each client. IDE vendors like JetBrains will certainly be doing something like this for their own IDEs, but I would guess they will hardwire it directly into their own APIs – I mean, that’s the sensible thing to do. Why help accelerate competing IDEs? There’s no incentive for it.
Similarly, model vendors are going to want a platform beyond the web at some point, and they seem to have all chosen VS Code. So if you are a VS Code user, you’re lucky because you have lots of choices for coding assistants. But model vendors aren’t going to make their stuff work across models, so if you like a particular coding assistant, but you don’t like their LLM, tough tiddly. Cody is the only system that I know of that’s trying to offer such a deep, rich product experience in every major editor and IDE, usable with any LLM, pluggable with any set of agents, as a universal platform.
Like I said. It’s insane. Fortunately, and I mean this very seriously – many colleagues are reporting the same – Cody has sped me up an enormous amount. More than really makes sense. It’s a sort of gestalt, but you find yourself tackling much larger problems and getting them done in days instead of weeks. Having Cody makes our ambitions for an IDE-automation platform feel tractable.
Of course I want it all for Emacs. All of it! But I ain’t spending 6 months writing the Cody client. We’ll cut that time way down. I aim for Cody to be writing emacs-lisp this summer, to accomplish ad-hoc tasks that normally I perform via Emacs “wizardry”, which means “reading Info pages for six hours.” And I aim to have a Cody platform API for you as soon as possible, so you can wire it up to your new monster truck of an IDE you’ve been working on.
This was supposed to be five pages, so I’d better wrap it. To summarize:
- Cody’s feature set is growing until it will encompass the whole IDE.
- Wiring up any one single major IDE to be fully automatable is a lot of work.
- Doing it in a universal way across all IDEs is even more work, plus a ton of per-IDE work.
- Work work work, money money money. This is an expensive project.
Props to Olaf Geirrson for being the mastermind and primary implementer behind our Cody client backend.
This is the most fun I’ve had in so many years. Making yourself faster is always fun.
And I think it’s going to pay off for us. We’ll see. Maybe those agents will write their own IDEs and get you to switch. Time will tell. M-x emacs-remind-me “20 years”
Anyway. Tell me what you think. This is geek stuff, I know. And blue-collar geek stuff, too. Plugins. Ugh, right? Let me know if you want to help! All five of you.